数据仓库分层架构 原理、作用与核心价值

数据仓库的分层架构是一种将数据处理过程进行逻辑和物理分离的设计方法,旨在构建一个清晰、高效、可维护的数据管理体系。其核心思想是通过不同的层级,对数据进行逐层加工、整合与沉淀,最终为上层的数据应用和分析提供稳定、可信的数据服务。
数据仓库分层架构的核心作用
- 清晰职责分离:每一层都有明确的职责边界,降低了系统的复杂性,便于团队分工协作。例如,数据工程师专注于底层数据的采集与处理,数据分析师则聚焦于上层的数据分析与建模。
- 数据质量管控:通过在各个层级建立数据清洗、转换和验证的规则,确保数据在向上层流动的过程中质量得到逐层提升,最终输出高质量、可信的数据。
- 提升处理效率与复用性:分层架构避免了重复计算。下层加工的通用数据结果可以被多个上层应用复用,减少了资源浪费,提升了整体处理效率。
- 增强灵活性与可扩展性:各层之间解耦,当业务需求变化或需要引入新的数据源时,可以独立地对某一层进行修改或扩展,而无需牵动整个体系。
- 简化数据溯源与运维:清晰的分层使得数据血缘关系一目了然,当数据出现问题时,可以快速定位到问题发生的具体层级,便于故障排查和影响范围评估。
典型的分层架构及各层详解
一个经典的数据仓库分层通常包含以下核心层级(具体命名可能因企业而异):
1. 数据采集层
- 作用:这是数据进入数据仓库的起点,主要负责从各种异构数据源(如业务数据库、日志文件、第三方API、物联网设备等)中抽取、加载数据。
- 核心任务:
- 数据抽取:以增量或全量的方式,定时或实时地从源系统获取数据。
- 数据加载:将抽取的原始数据几乎不做处理地存储到数据仓库的底层存储中,因此这一层的数据也称为“操作数据存储”或“贴源数据层”。
- 格式统一:可能进行简单的格式标准化,但核心是保留数据的原始状态,便于后续问题回溯。
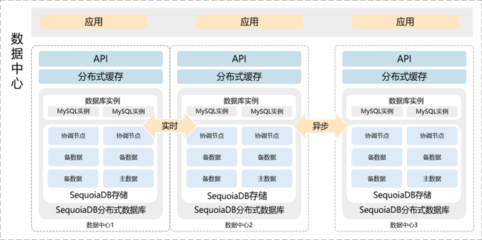
2. 数据存储与分析核心层
这一部分是数据仓库的“心脏”,通常进一步细分为:
- 明细数据层:
- 对采集层的原始数据进行清洗、转换、集成和规范化。例如,统一字段格式、处理空值、关联多表数据形成宽表、遵循一致的业务规则等。
- 此层的数据是面向主题的、干净的、粒度的明细数据,是后续所有数据加工的单一可信来源。
- 汇总数据层 / 服务数据层:
- 基于明细数据层,根据具体的业务分析需求,进行轻度或高度的汇总、聚合。例如,生成日/月销量报表、用户行为画像宽表、部门级KPI指标等。
- 这一层的数据已经过深度加工,查询性能高,旨在直接支持数据应用、报表和即席分析,因此也常被称为“数据集市”。
3. 数据处理和存储支持服务
这不是一个独立的分层,而是贯穿整个架构的支撑体系:
- 数据处理服务:指执行数据清洗、转换、聚合等任务的计算引擎(如Apache Spark, Flink, Hive, Tez等)及其调度管理系统(如Apache Airflow, DolphinScheduler等)。它们负责驱动数据在各层之间按既定逻辑和计划流动。
- 数据存储服务:指各层数据物理存储的介质和技术选型。例如,采集层和明细层可能使用HDFS、对象存储或低成本分布式数据库来存储海量原始数据;汇总层和应用层则可能使用MPP数据库、云数据仓库或OLAP引擎(如ClickHouse, StarRocks)来提供高性能查询。
数仓分层带来的核心好处
采用分层架构的数据仓库带来了多重收益:
- 对业务:能够快速、灵活地响应多变的业务分析需求,提供及时、准确的数据洞察,支撑决策。
- 对技术:构建了标准化的数据处理流水线,提升了开发效率、资源利用率和系统稳定性,降低了长期维护成本。
- 对数据本身:建立了从原始数据到可信数据资产的规范化生产流程,保障了数据的一致性、准确性和安全性,使数据真正成为企业的核心资产。
通过清晰的数据仓库分层架构,企业能够将杂乱无章的数据流,梳理成一条条高效、可控的数据生产线,源源不断地为智能决策和业务创新输送“高质量燃料”。
如若转载,请注明出处:http://www.quickagrade.com/product/66.html
更新时间:2026-06-19 09:17:48