新版教材第20章学习笔记 微服务系统分析与设计中的数据处理和存储支持服务
在微服务架构中,数据处理与存储支持服务是确保系统可靠性、可扩展性和数据一致性的核心基石。本章深入探讨了微服务系统分析与设计中,针对数据处理和存储支持服务的关键考量、模式与实践。
一、微服务数据管理面临的挑战
与单体架构集中式数据库不同,微服务强调每个服务拥有独立的领域数据和数据库,实现数据自治。这带来了诸多挑战:
- 数据分散与一致性:事务跨越多个服务时,传统的ACID事务难以保证,需引入分布式事务或最终一致性模式。
- 数据查询复杂化:跨多个服务的数据关联查询变得困难,需要特定的设计模式来支持。
- 数据冗余与同步:为实现服务解耦和性能优化,数据可能需要在不同服务间存在冗余副本,并建立同步机制。
二、核心设计模式与策略
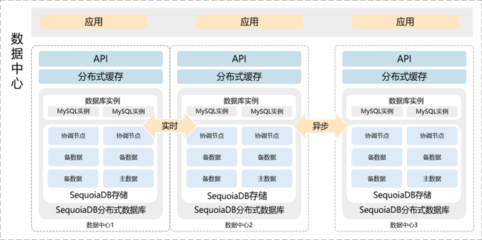
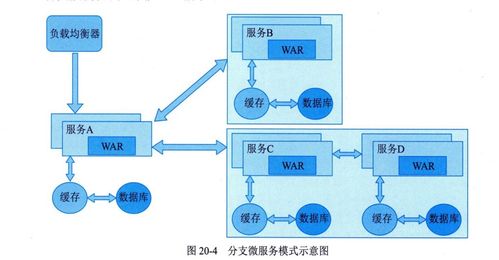
- 数据库按服务分离:每个微服务管理其专属的、私有的数据库(可以是不同类型,如SQL、NoSQL),这是实现松耦合的基本原则。
- 命令查询职责分离(CQRS):将数据更新操作(命令)与数据查询操作分离,通常使用不同的模型和存储结构。命令端处理业务逻辑并更新写库,查询端则通过优化过的读模型(可能来自独立的读库或缓存)提供高效查询,有效解决了复杂查询与读写负载不均衡问题。
- 事件溯源(Event Sourcing):不直接存储实体的当前状态,而是将状态的变化存储为一系列不可变的事件序列。通过重放事件可以重建任何时间点的实体状态。该模式能提供完整的审计日志、支持时间旅行查询,并自然与事件驱动架构集成,便于发布领域事件供其他服务订阅。
- Saga模式:用于管理跨多个服务的分布式事务。它将一个长事务拆分为一系列本地事务,每个本地事务完成后发布一个事件或消息来触发下一个服务操作;若某个步骤失败,则通过补偿性事务(回滚操作)来撤销之前已完成的步骤,保证最终一致性。Saga可分为编排式(由中央协调器驱动)和协同式(由服务间事件/消息驱动)两种。
三、存储支持服务的关键组件
- API网关:作为系统入口,可集成聚合查询功能,将来自多个微服务的查询结果组合后返回给客户端,简化前端调用。
- 消息中间件/事件总线:实现服务间异步通信与事件传播的核心基础设施(如Kafka, RabbitMQ)。用于数据变更事件的发布/订阅,驱动数据副本的异步同步,是实现最终一致性和服务解耦的关键。
- 缓存服务:引入Redis、Memcached等缓存层,存储热点数据或聚合后的查询结果,显著提升读取性能和系统吞吐量。需注意缓存一致性策略(如失效、更新)的设计。
- 搜索与分析服务:对于全文搜索、复杂分析查询等需求,可将数据从业务数据库中异步同步到Elasticsearch、ClickHouse等专用存储中,实现读写分离与能力扩展。
- 配置中心与秘钥管理:集中管理各微服务的数据源连接配置、访问密钥等敏感信息,提升安全性与可管理性。
四、实践分析与设计要点
- 数据边界划分:在领域驱动设计指导下,根据业务边界(限界上下文)划分数据所有权,确保数据与服务的领域模型对齐,这是设计成功的前提。
- 技术选型多元化:根据数据特性(结构化、文档、图、时序等)和访问模式(高并发读、复杂事务、海量写入等),为不同服务匹配合适的数据库技术(如关系型、MongoDB、Cassandra、Neo4j等),发挥“最佳工具”效应。
- 监控与可观测性:建立全面的监控体系,追踪跨服务的数据流、事务链路、存储性能与延迟,快速定位数据一致性问题或性能瓶颈。
- 数据治理与安全:在数据分散的背景下,需统一考虑数据生命周期管理、隐私合规(如GDPR)、加密传输与存储、访问控制与审计等全局性治理策略。
微服务下的数据处理与存储设计是一个权衡艺术,需要在数据一致性、可用性、性能、复杂度与开发运维成本之间找到平衡点。深入理解上述模式与组件,并结合具体业务场景进行合理选型与设计,是构建健壮、灵活的现代化微服务系统的关键所在。
如若转载,请注明出处:http://www.quickagrade.com/product/83.html
更新时间:2026-06-19 10:36:56