Java对象在内存中的结构与数据处理、存储支持服务探析
在Java应用程序的运行过程中,对象作为数据与操作的载体,其内存结构的理解对于性能优化、问题排查及系统设计至关重要。现代数据处理与存储支持服务为这些对象的高效管理提供了坚实后盾。本文将深入探讨Java对象在内存中的布局,并分析其与后端数据处理、存储服务的关联。
一、 Java对象在内存中的结构
Java对象在堆内存(Heap)中的存储结构通常包含三个主要部分:对象头(Header)、实例数据(Instance Data)和对齐填充(Padding)。
- 对象头(Header):存储对象的元数据。
- Mark Word:用于存储对象自身的运行时数据,如哈希码、GC分代年龄、锁状态标志、线程持有的锁、偏向线程ID等。这部分数据在32位和64位虚拟机上长度不同,并且会根据对象状态复用存储空间。
- 类型指针(Klass Pointer):指向对象所属类元数据(Klass)的指针,虚拟机通过此指针确定对象是哪个类的实例。在开启指针压缩(-XX:+UseCompressedOops,默认开启)的64位JVM中,此指针通常为4字节。
- 数组长度:如果对象是数组,对象头中还会包含一块用于记录数组长度的数据。
- 实例数据(Instance Data):存储对象中各个类型的字段内容,包括从父类继承下来的字段。字段的存储顺序会受到虚拟机分配策略参数(-XX:FieldsAllocationStyle)和字段在Java源码中定义顺序的影响。基本类型数据会直接存储,而引用类型则存储指向另一块内存区域的指针。
- 对齐填充(Padding):并非必然存在。HotSpot VM要求对象起始地址必须是8字节的整数倍,因此当对象头与实例数据的总大小不是8的倍数时,就需要通过对齐填充来补全。这主要是为了内存寻址的效率。
内存布局示例:一个简单的User对象(包含int id, String name字段)在内存中,会先有对象头,然后是id的4字节数据,接着是指向String对象的引用(通常4或8字节),最后可能有填充字节。其实际占用的内存空间可通过工具(如JOL库)精确分析。
二、 数据处理与存储支持服务对Java对象管理的意义
Java对象在内存中创建和消亡,但其承载的数据往往需要持久化、共享或进行复杂计算。这就需要后端的数据处理与存储服务提供支持。
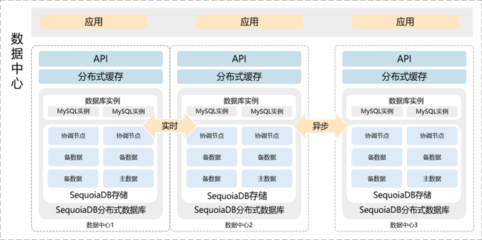
- 序列化与反序列化:这是内存对象与存储/传输格式转换的桥梁。当需要将对象存入数据库(如MySQL)、缓存(如Redis)、消息队列(如Kafka)或进行网络传输(RPC调用)时,对象必须被序列化为字节流(如使用JDK序列化、JSON、Protobuf等)。反之,从这些服务读取数据时,则需要反序列化回内存中的Java对象。理解对象内存结构有助于选择或设计高效的序列化方案。
- ORM框架与内存映射:对象关系映射框架(如MyBatis, Hibernate)的核心工作之一,就是将数据库表中的行数据,高效地组装成内存中的Java对象(及其对象图)。这个过程涉及字段映射、懒加载、缓存等机制,其效率与对象的内存结构紧密相关。优化实体类设计(如避免过深的继承层次、谨慎使用大对象)能提升ORM性能。
- 缓存服务:分布式缓存(如Redis, Memcached)常被用来存储热点数据对象,以减少数据库压力和访问延迟。缓存中的对象通常是序列化后的形态。对象的设计(如大小、复杂度)直接影响序列化/反序列化的开销和网络传输效率,进而影响缓存性能。有时,会将对象拆分为多个更细粒度的缓存键来优化。
- 大数据处理与列式存储:在处理海量数据时(如使用Spark、Flink),数据常以内部数据结构(如Row,本质也是对象)在内存中流转。列式存储格式(如Parquet, ORC)在持久化时,改变了数据的组织方式,使其更利于压缩和批量分析。了解对象内存布局有助于理解这些框架为何能进行高效的序列化(如Spark的Tungsten项目)和内存管理。
- 堆外内存与网络传输:为了规避GC停顿、实现零拷贝或与本地库交互,高级应用会使用堆外内存(DirectByteBuffer)。Netty等网络框架大量使用堆外内存来存储和传输数据。数据从Java对象写入堆外缓冲区,或反之读取,都涉及高效的内存拷贝与布局转换,这与对象的字段排列息息相关。
三、 实践启示与优化方向
- 对象设计优化:尽量使对象小巧、扁平,避免不必要的字段,谨慎使用大对象(如大数组),以降低内存占用和序列化开销。
- 序列化选型:根据场景选择高效序列化协议(如Protobuf、Kryo、Hessian),它们能生成更紧凑的字节流,比JDK原生序列化性能更优。
- 缓存策略:考虑缓存对象的粒度与形态,对于复杂对象,可缓存其部分字段或计算后的结果。
- 监控与剖析:利用JVM工具(如MAT, VisualVM)分析堆内存快照,识别内存中重复、冗余或过大的对象结构,结合业务逻辑进行优化。
###
Java对象的内存结构是JVM层面的微观细节,而数据处理与存储支持服务是应用架构中的宏观支撑。深刻理解前者,能让我们更好地驾驭后者,从而在设计高效、可扩展的数据驱动型应用时做出更明智的决策。从对象字段的排列,到跨进程的数据流动,再到磁盘上的字节布局,这条数据链路上的每一环都值得我们深入探究与优化。
如若转载,请注明出处:http://www.quickagrade.com/product/67.html
更新时间:2026-06-19 01:46:00